

By Peter Harding
Rosette Name Indexer offers myriad configuration options to improve name matching accuracy and speed. There is no single best setup. It depends largely on your business goals and the specific phenomena in your name data (such as transliteration issues, initials, nicknames, and missing name components). As such, it can be bewildering to figure out where to start. This article shares best practices for assessing your needs and tuning the system to improve performance with the least effort for the biggest impact.
The steps are:
- Understanding your business goals
- Tuning for accuracy
- Create representative test and truth data
- Assess high-frequency and unique name tokens
- Create a framework for automated testing and scoring results
- Establish your baseline accuracy and speed
- Focus your accuracy tuning
- Tuning for speed
- Create test data
- Trade-offs between speed and recall
Understanding your business goals
People choose Rosette Name Indexer to improve name matching accuracy without compromising speed. The business goal might be to cut false positives in half or reduce human review to looking at only 5% of matches instead of 20%. How ever you define it, this goal will let you know when you have “tuned enough.” The human reviewer could be a passport control officer at the border, an investigator for a bank’s financial compliance department, or a doctor’s office receptionist looking up a patient record.
Tuning for accuracy
Create representative test and truth data
The first step is to assemble a test data set that is representative of the real-world data your system will process. It is the indispensable yardstick by which you will measure the accuracy of the system. A good place to start is with historical query data. Your test data should contain examples of query results that were considered a “good match” and a “bad match.” A good match is one that a human reviewer should check. A bad match is one which is so obviously wrong that a human reviewer shouldn’t even see it.
The "answer sheet” to your test data is called the truth data. For each pair of names in the test data, your truth data indicates whether it’s a match (true positive) or not a match (true negative).
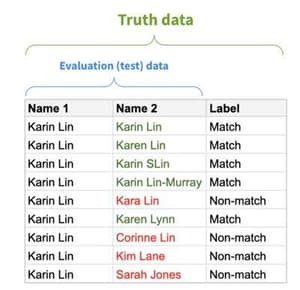
Some questions to ask include:
- Do the different lists inconsistently format the order of names? For example, are some ordered “surname, given name, middle name” and others as “given name and/or middle name, surname”?
- Is one list often missing name components (middle names, one name of a two-word Spanish surname) or have sparsely populated fields like dates of birth?
- What languages appear in the data? Is it all English or are there Cyrillic, Chinese, and Japanese scripts? Your test data should have language coverage proportional to the real data.
If you cannot get real data and are forced to generate synthetic test data, it should resemble the real data as closely as possible.
Assess high-frequency and unique name tokens
Second, make a list of the high-frequency name phenomena that your current system handles well or badly. If this is a new system, look at real-world data to see what phenomena it contains.
Finally, calculate the uniqueness of name tokens in the historical data and the indexed data. Why? The match score “Mr. John Smith” compared to “Mr. John Thompson” will be skewed high as two-thirds of the name is an exact match. From your name token frequency list, you can then:
- Easily identify candidates for stop word removal, such as “PhD” if it appears frequently in a database of academics
- Find “junk” words, such as a stray “the” in a name field (“the John Smith”)
- Identify tokens that should be given low weight in the match score. Examples might include "system” or “association” in organization names.
Replacing Rosette Name Indexer’s default files for stop words and low-token weight names with the frequent name tokens specific to your data increases the accuracy of Rosette Name Indexer.
Create a framework for automated testing and scoring results
Taking time to build an automated testing and scoring framework will pay off many times over. When setting up Rosette Name Indexer, you need a quick way to measure the accuracy and performance of your current system (the baseline), after you integrate Rosette Name Indexer, and again after each configuration change. Furthermore, when (not if) conditions change in the future, you’ll want to reassess performance, such as when:
- You add a new list of names with new name phenomena issues
- You add a list with names in a new language
- Industry regulations change, such that your system must perform fuzzier matches or incur fewer false negatives
In any of these cases, a test harness that can automatically compute the precision, recall, and F-score of the system will be invaluable.
Establish your baseline accuracy and speed
Now, with your test data establish your system’s baseline performance in terms of accuracy and speed. Doing so is as simple as running the test data through your testing framework to measure the precision, recall, and F-score of your existing system in addition to query throughput and query latency. The purpose is to benchmark your current state before you integrate Rosette Name Indexer or make any changes.
Focus your accuracy tuning
Refer to your business goals as to how much improvement you would like to see. Let’s suppose you want to reduce your number of false positives by 66%.
Rosette Name Indexer has more than 100 parameters, but only a handful apply for any given name phenomena, so begin by looking at the ones related to the most-frequently occurring name phenomena in your data. Gather the subject matter experts (SMEs) in your domain. If this is financial compliance, the SMEs would be the investigators, and for border security, border agents. Run the relevant historical queries with the match threshold set low, around 68-70%, and see what results come back. Are you seeing good or bad hits? If there are obvious false positives, tackle those first. Save the borderline cases for later.
Let’s suppose you first tackle names with initials. Now adjust the penalty on an initial match until you start to see new problems. It’s important to understand these scenarios and document your decision for each pattern. Repeat for the next most frequently occurring name phenomena until you have reached your business goal.
In the end, only you and your SMEs can determine the right set of configurations. It is possible that instead of reducing human review from 20% of matches to 5%, 7% is the best fit for your business needs because that is the point at which the false positives are of high enough quality that you want a human agent to review those results.
Tuning for speed
Create test data
Tuning for high throughput or low query latency requires a different test set than for accuracy. Although you want the data composition — in terms of name phenomena and languages — to be similar to the test set evaluating accuracy, here the emphasis is on size. If your real-life data is 80 million names, a test set with 10 million names won’t be adequate. However, because you aren’t testing for accuracy (that requires unique name pairs) you can simply make 800,000 copies of your testing-for-accuracy data set of 100 examples to create a set of 80 million names.
Trade-offs between speed and recall
A basic understanding of Rosette Name Indexer’s query process is helpful to understand the options for increasing query throughput and reducing query latency (the time it takes a query to return a result). Rosette Name Indexer takes a two-pass approach. The first pass is a high-speed, high-recall pass through a name list to find the most likely match candidates, to quickly eliminate most of the names. A given number of these match candidates go on to the second pass which uses high-precision, but slower, AI to consider other factors and freshly score all the candidates against the query name. (See details of match scoring.)
The largest determiner of speed is the configuration for Rosette Name Indexer’s window size. Window size refers to the number of match candidates from the first pass sent to be rescored by the second pass. The first pass is designed to catch all matches (false negatives are at zero). The likelihood of false negatives increases as the window size decreases, but the query latency also increases as the window size decreases.
The window size configuration is customizable to the per-query level. Suppose that for 99% of queries, a window size of 200 is more than adequate, but then with the very common name “John Smith” you need a window size of 2,000 to avoid false negatives. Rosette Name Indexer allows you to set a “per-query” match profile (set of configurations) so that only when specific, extremely frequent names appear in a query, the window size is increased to 2,000 to avoid missing matches.
In conclusion
The iterative nature of the tuning process in Rosette Name Indexer means that for a large system with millions of names on a list, after the initial setup and tuning, it can potentially take a few more months of trying, testing, using, and readjusting until the system is performing optimally for your data. As new data is added or requirements change, it is good to check the system performance again. The Babel Street professional services team is often engaged to perform an initial “getting started” seminar and then engaging as needed to help Rosette Name Indexer users tune their system.
Contact us to find out how Babel Street can help you achieve your business goals.
Peter Harding is the Director of Professional Services at Babel Street. He led the professional services team that worked with the U.S. Customs and Border Protection and the UK Home Office Border, Immigration and Citizenship System to tune Rosette Name Indexer for optimal performance on their respective border security systems.
Related articles
- How to Improve Matching with Rosette Plug-in for Elasticsearch
- How to Measure Accuracy of Matching Technology
- 7 Things to Look for in a Matching Solution
- How to Evaluate and Buy Matching Technology (webinar recording)
- Understanding Match Scoring in Rosette
- More than Matching: Rosette Intelligently Matches Postal Addresses and Dates
All names, companies, and incidents portrayed in this document are fictitious. No identification with actual persons (living or deceased), places, companies, and products are intended or should be inferred.





