

By Chini Sinha
Elasticsearch developers who want to fuzzy search names across multiple fields and cover the spectrum of name variations (sometimes two or more in a single name), know how difficult and frustratingly complex setting up fuzzy name matching can be. Until now, the solution has not been completely satisfactory, comprehensive, nor clean, but that’s all changed.
The Babel Street Rosette name matching integration for Elasticsearch solves the fuzzy name matching issue.
Fuzzy Name Search Issues in Elasticsearch
Elasticsearch can be configured to provide some fuzziness by mixing its built-in edit-distance matching and phonetic analysis with more generic analyzers and filters. However, this approach requires a complex query against multiple fields, and recall is completely determined by Soundex/metaphone (phonetic similarity) and Lucene edit distance1. As for precision, it is difficult to guarantee that the best results will be at the top. Lucene document scores are 32-bit digits, and while higher scores indicate better matches, the scores are not along a consistent continuum (such as 0 to 100), making it impossible to establish match thresholds, to confidently know that “scores above 80” are of a particular match confidence. Additionally, other types of variations (e.g., swapped name order) are taken into account in calculating the similarity.
Best-practice for fuzzy name matching using just Elasticsearch “out of the box” is a multi_field type with a separate created field for each type of name variation:
"mappings": { ... "type": "multi_field", "fields": {
"pty_surename": { "type": "string", "analyzer": "simple" },
"metaphone": { "type": "string", "analyzer": "metaphone" },
"porter": { "type": "string", "analyzer": "porter" } ...
However, this name matching approach has trouble matching names when there is more than one type of spelling variation involved in the comparison.
“Ignacio Alfonso Lopez Diaz” v. “LobEzDiaS, Nacho”
The above pair of names differ by differently ordered name components, a missing initial, two spelling differences, a nickname for the first name and a missing space.
And, for developers that want a name field type that also:
- Contributes a score specific to name matching phenomena
- Is part of queries using many field types
- Has multiple fields per document
- Has multiple values per field
…then Rosette Name Indexer is the way to go.
HOW ROSETTE WORKS INSIDE ELASTICSEARCH
The Rosette integration is through the Elasticsearch plugin mechanism. It contains a custom mapper which does all the complex matching for many types of name phenomena behind the scenes.
PUT /test/_mapping
{
"properties" : {
"name" : { "type:" : "rni_name" }
"aka" : { "type:" : "rni_name" }
}
}
At index time:
The Rosette integration indexes keys for different phenomena (types of name variations) in separate (sub) fields/
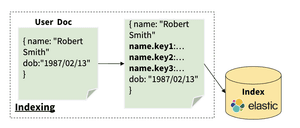
At query time:
Rosette generates analogous keys for a custom Lucene query that finds good candidates for re-ranking.
POST /test/_search
{
"query" : {
"match" : {
"name" : "primary_name" : "{\"data\" : \"LobEzDiaS, Chuy\", \"entityType\" : \"PERSON\"}"
}
},
"rescore" : {
"window_size" : 200,
"query" : {
"rescore_query" : {
"function_score" : {
"name_score" : {
"field" : "name",
"query_name" : "LobEzDiaS, Chuy"
}
}
},
"query_weight" : 0.0,
"rescore_query_weight" : 1.0
}
}
}
The name_score function matches the query name against the indexed name in every candidate document and returns the similarity score which is on a consistent continuum of match confidence from 0 to 1.
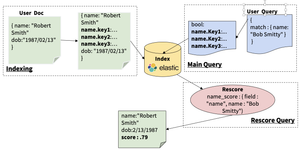
There are rescoring parameters that can be tweaked to give the system more speed or more accuracy. Tagging fewer documents for reranking, will increase query execution speed — because fewer names will be considered in the rescore query. However, if too few names are sent to the rescore query, potentially good matches lower down the main query’s list might not get rescored higher.
- window_size – specifies how many documents from the base query should be rescored
- score_to_rescore_restriction – (added by Babel Street) sets the score threshold that the document must meet to be rescored.
- window_size_allowance – (added by Babel Street) dynamically controls the window size for rescoring. No more than window_size names will be scored.
- score_if_null – (added by Babel Street) when enabled, the set value is returned when a field is missing from the document.
- filter_out_scores_below – (added by Babel Street) sets the minimum score required for a given field match to be returned by the rescorer.
Within the entire query, the developer can decide how much weight to give to the name match versus the overall query match.
- rescore_query – Calls the name_score function to get a score, and then combines rescore_queries to query across multiple fields
- query_weight – Controls how much weight is given to the main query, and allows the user to include queries on other non-name fields
- rescore_query_weight – Specifies the weight to give to the rescored query
Example:
GET test/_search
{
"query": {
"match": {
"primary_name": "{\"data\" : \"LobEzDiaS, Chuy\", \"entityType\" : \"PERSON\"}"
}
},
"rescore": {
"window_size": 200,
"rni_query": {
"rescore_query": {
"rni_function_score": {
"name_score": {
"field": "primary_name",
"query_name": {
"data": "LobEzDiaS, Chuy",
"entityType": "PERSON"
},
"score_to_rescore_restriction": 1,
"window_size_allowance": 0.5
}
}
},
"query_weight": 0,
"rescore_query_weight": 1
}
}
}
IN A NUTSHELL
The Rosette name matching integration adds:
- Custom field type mapping
- Splits a single field into multiple fields covering different phenomena
- Supports multiple name fields in a document
- Intercepts the query to inject a custom Lucene query.
Custom rescore function:
- Rescores documents with an algorithm specific to name matching
- Limits expensive calculations to only top candidate documents
- Is highly configurable
The Rosette name matching integration was built and tested with Elasticsearch 8.8.1 as of June 2023.
For more information about the Rosette plugin for fuzzy name searching of people, organizational or place names, contact Babel Street to request a demo or copy of a product evaluation.
1 Edit distance refers to the number of changes it takes to get from one spelling to another. Thus “ax” to “axe” has an edit distance of 1 (add “e”), and “axs” to “axe” has an edit distance of 2 (remove “s” add “e”).





