

By Tina Lieu
If name matching or searching is mission critical for your business, the first question you’ll likely ask about any tool is, “How accurate is it?” However, what you really need to know is, “How do I measure accuracy on my data?” Not all data is equal, and your data is the most important criteria for finding a tool that will perform optimally with it. You need two things in order to do a thorough comparison of name matching tools:
- A rigorous, objective and repeatable comparison process with quantifiable metrics
- A good set of evaluation (aka, test) data.
Comparing the accuracy of these two tools begins with having the right test dataset.
How to create a good test dataset for evaluating name matching tools
What does the right dataset look like? These pictures sum it up:


Your test dataset should contain name variations your current solution does and doesn’t handle well, plus any variations in your data.
If you have many types of issues, it’s OK if your test dataset is sizable. But don’t make it big for the sake of being big.
The most common mistakes in test data creation are:
- Creating synthetic or derived data with limited types of variations and applying the variation to every name
- Solely focusing on names that your current solution can’t handle; you should include variations that are handled well
- Testing scenarios that aren’t in your real world data, such as asking the tool to parse “asfadfPETERasdfasdf”
- Testing fields that almost never appear in real world data; for example, “date of birth” if it appears in only 20% of records.
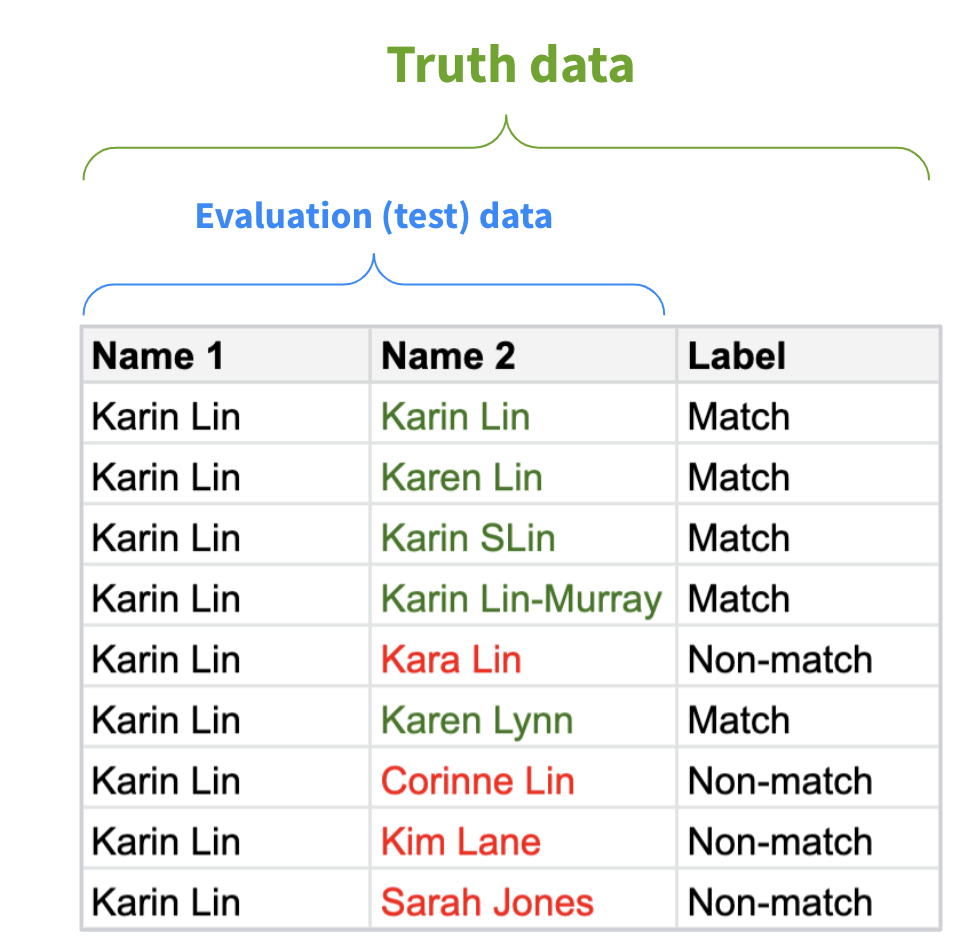
Once you have your test dataset, label it, and that is your “truth data.” This is essentially the answer sheet for these questions:
- Which names should match?
- Which names should not match? (You don’t want to see your tool get high scores on names that shouldn’t match.)
Here’s an example of truth data:
How to measure accuracy in your evaluation
Now that you have your test data and truth data, try them on your existing name matching solution. Score the results using precision and recall as follows:
- When the system is correct in reporting a match, that’s a “true positive” (TP).
- When the system is correct in reporting a non-match, that’s a “true negative” (TN).
- When the system incorrectly reports a match when it should be a non-match, that’s a “false positive” (FP).
- When the system incorrectly reports a non-match when it should be a match, that’s a “false negative” (FN).
Plug the totals above into these equations:

What is commonly called “accuracy” is the F-score (F1), which is calculated using precision (P) and recall (R).

The F-score is the industry standard for how to measure accuracy. However, since F-score is jthe harmonic mean of precision and recall, you can get the same F-score with different values of each. Here you have to figure out the mix of accuracy you require.
Evaluate your business needs
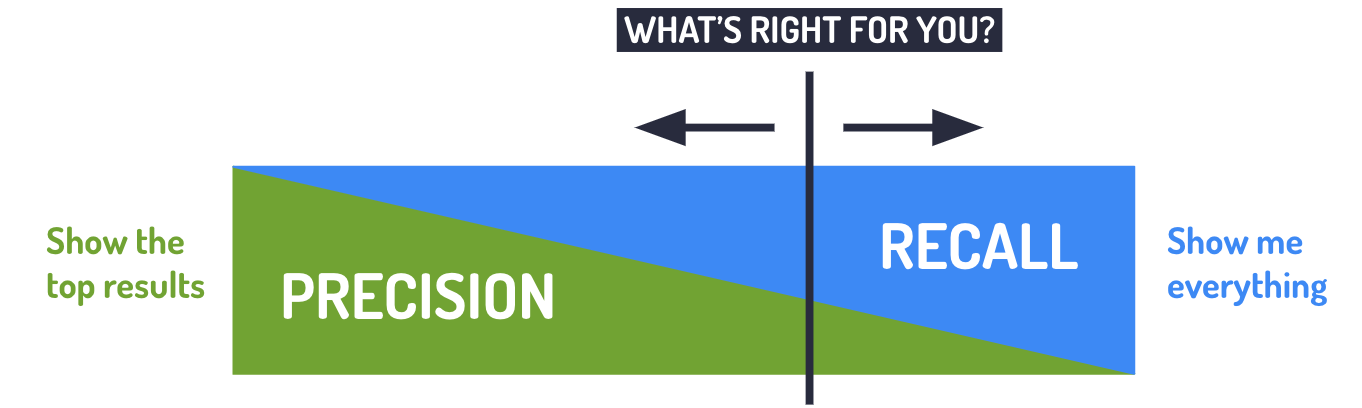
Generally speaking, precision and recall have an inverse relationship. Recall will be greater if you look at more results, but those results will have more incorrect answers (lower precision). Given that 100% precision and 100% recall are unattainable, you need to determine which one your business needs more of.
If you are screening passengers against a no-fly list, you want to maximize recall so that you don’t miss even one potential terrorist. If you do watchlist screening for anti-money laundering compliance, and false positives are currently 90% of your results, (thus making it impossible to find the true positives), you need more precision.
Configurability
The solution you choose should give you the flexibility to configure the matching behavior of the tool. Does the tool let you increase the default penalty for a missing name component? Does the tool let you weigh surnames more heavily than given names if they are more authoritative?
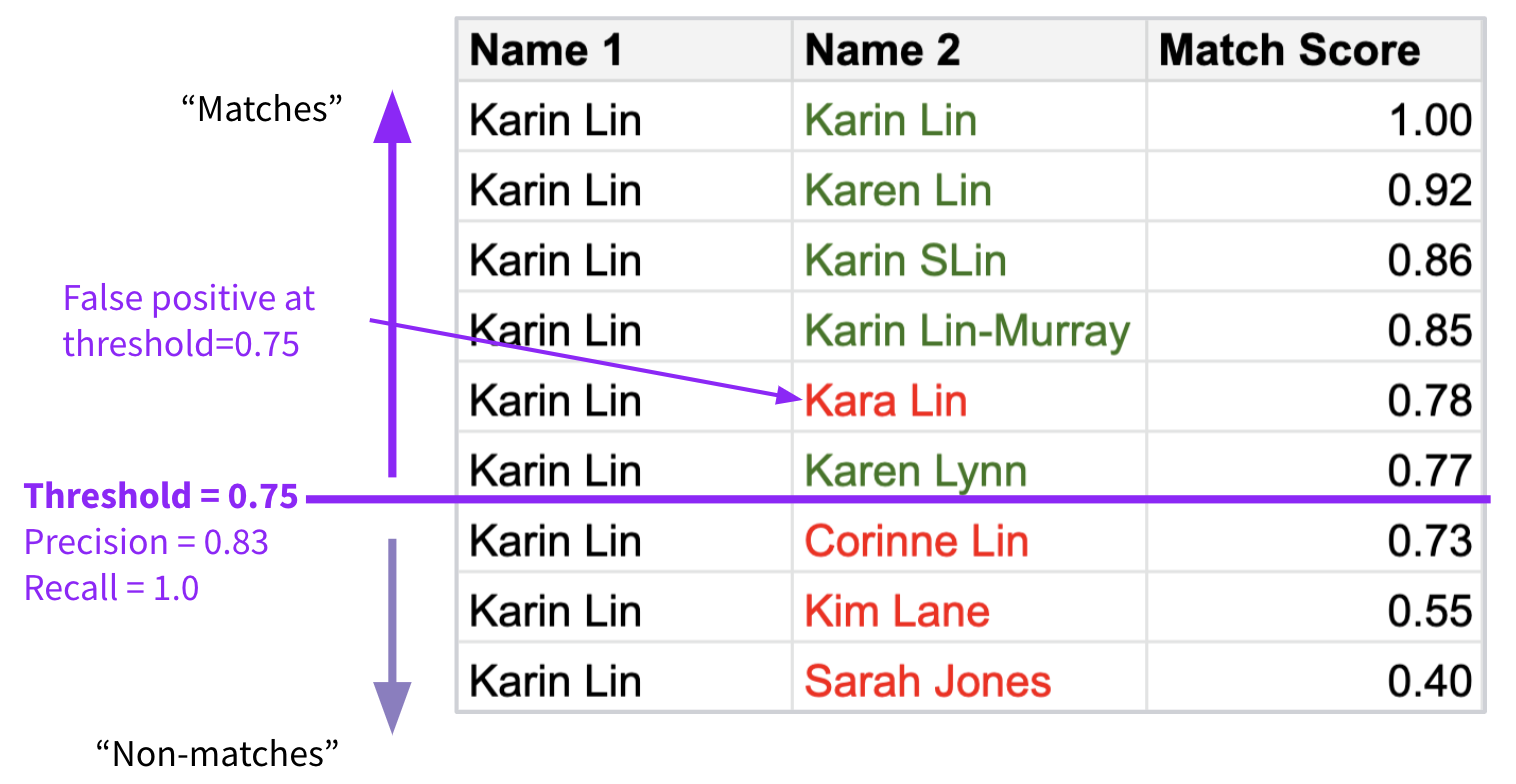
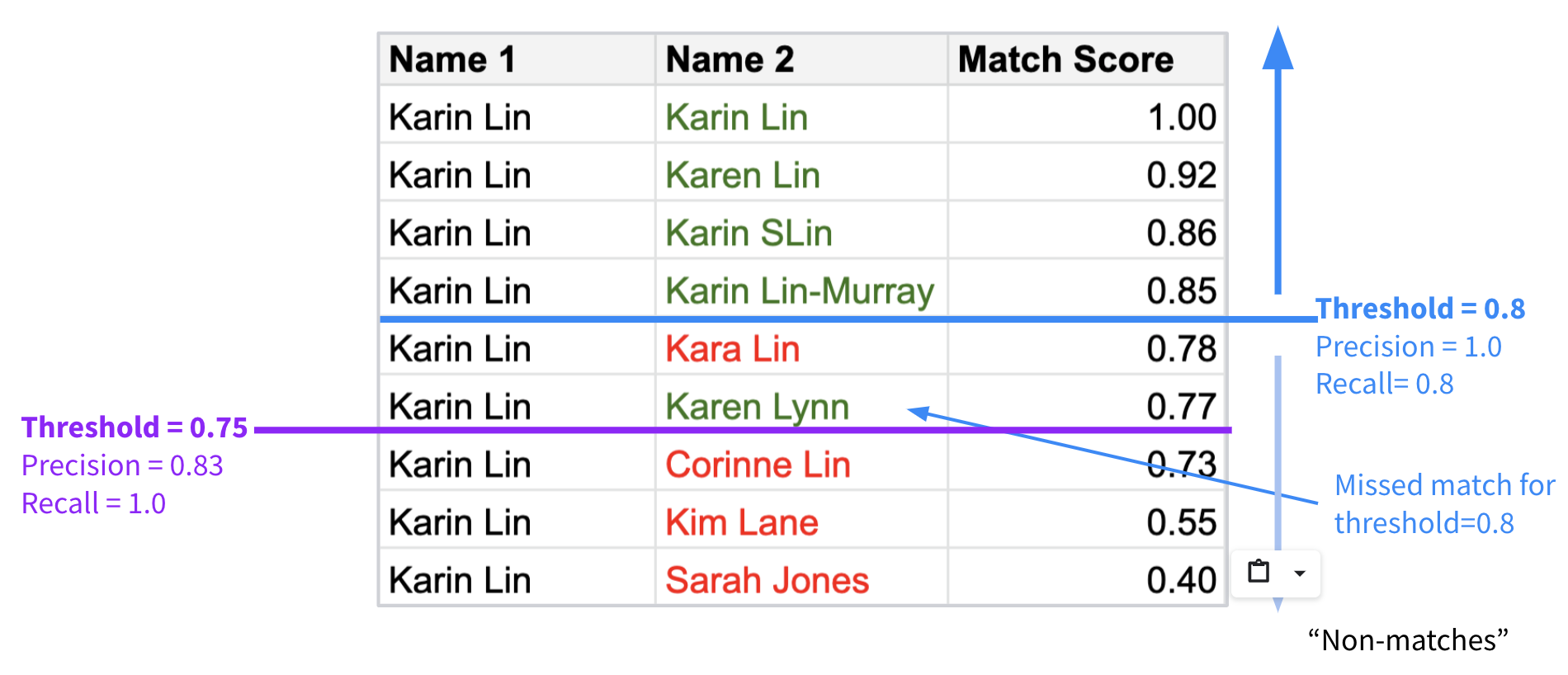
Furthermore, if you can set a match threshold, you can set the accuracy mix. For example, if all pairs that score .80 and higher are considered a match, you will get higher precision than if you set the threshold at .75. But .75 will give you higher recall.
In brief
The steps for how to measure accuracy are:
- Gather and label truth data
- Use real data
- Make sure the variations in your data also appear in the test set
- Evaluate the accuracy of your current system
- Use the test set
- Measure precision, recall, and accuracy
- Evaluate other solutions
- Repeat steps in #2
- Consider your business needs
- What mix of accuracy do you need?
- Can you configure the solution to meet your desired accuracy mix?
- Can you set a match threshold?
- Decide on a tool
Learn more
- Read the e-book 7 Things to Look for in a Matching Solution





